不吹牛,吃下我这篇,面试第一关算是过了(2)
时间: 2022-02-24 10:25 作者: liqianqian1116 点击次数:
为什么 JDK 1.8 要对 HashMap 做红黑树这个改动?
主要是避免 hash 冲突导致链表的长度过长,这样 get 的时候时间复杂度严格来说就不是 O(1) 了,因为可能需要遍历链表来查找命中的 Entry。
为什么定义链表长度为 8 且数组大小大于等于 64 才转红黑树?不要链表直接用红黑树不就得了吗?

因为红黑树节点的大小是普通节点大小的两倍,所以为了节省内存空间不会直接只用红黑树,只有当节点到达一定数量才会转成红黑树,这里定义的是 8。
为什么是 8 呢?这个其实 HashMap 注释上也有说的,和泊松分布有关系,这个大学应该都学过。
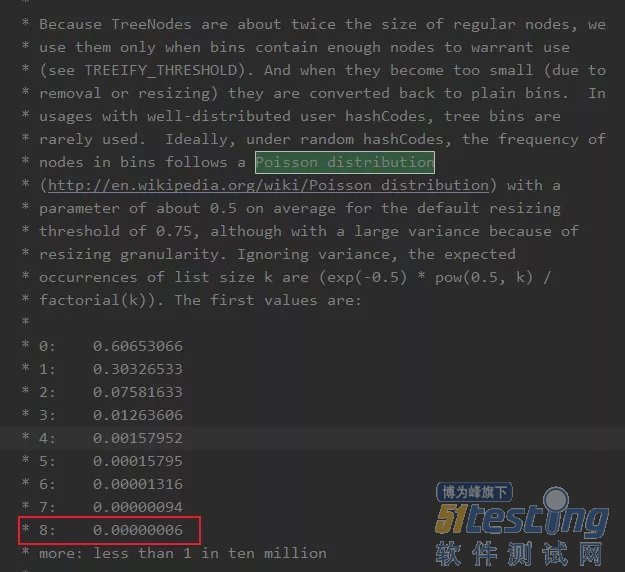
简单翻译下就是在默认阈值是 0.75 的情况下,冲突节点长度为 8 的概率为 0.00000006,也就概率比较小(毕竟红黑树耗内存,且链表长度短点时遍历的还是很快的)。
这就是基于时间和空间的平衡了,红黑树占用内存大,所以节点少就不用红黑树,如果万一真的冲突很多,就用红黑树,选个参数为 8 的大小,就是为了平衡时间和空间的问题。
为什么节点少于 6 要从红黑树转成链表?
也是为了平衡时间和空间,节点太少链表遍历也很快,没必要成红黑树,变成链表节约内存。
为什么定了 6 而不是小于等于 8 就变?
是因为要留个缓冲余地,避免反复横跳。举个例子,一个节点反复添加,从 8 变成 9 ,链表变红黑树,又删了,从 9 变成 8,又从红黑树变链表,再添加,又从链表变红黑树?
所以余一点 ,毕竟树化和反树化都是有开销的。
那 JDK 1.8 对 HashMap 除了红黑树这个改动,还有哪些改动?
・ hash 函数的优化
・ 扩容 rehash 的优化
・ 头插法和尾插法
・ 插入与扩容时机的变更
hash 函数的优化
1.7是这样实现的:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
而 1.8 是这样实现的:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
具体而言就是 1.7 的操作太多了,经历了四次异或,所以 1.8 优化了下,它将 key 的哈希码的高16位和低16位进行了异或,得到的 hash 值同时拥有了高位和低位的特性,这样做得出的码比较均匀,不容易冲突。
这也是 JDK 开发者根据速度、实用性、哈希质量所做的权衡来做的实现:

扩容 rehash 的优化
按照我们的思维,正常扩容肯定是先申请一个更大的数组,然后将原数组里面的每一个元素重新 hash 判断在新数组的位置,然后一个一个搬迁过去。
在 1.7 的时候就是这样实现的,然而 1.8 在这里做了优化,关键点就在于数组的长度是 2 的次方,且扩容为 2 倍。
因为数组的长度是 2 的 n 次方,所以假设以前的数组长度(16)二进制表示是 01000,那么新数组的长度(32)二进制表示是 10000,这个应该很好理解吧?
它们之间的差别就在于高位多了一个 1,而我们通过 key 的 hash 值定位其在数组位置所采用的方法是 (数组长度-1) & hash。我们还是拿 16 和 32 长度来举例:
16-1=15,二进制为 00111
32-1=31,二进制为 01111
所以重点就在 key 的 hash 值的从左往右数第四位是否是 1,如果是 1 说明需要搬迁到新位置,且新位置的下标就是原下标+16(原数组大小),如果是 0 说明吃不到新数组长度的高位,那就还是在原位置,不需要迁移。
所以,我们刚好拿老数组的长度(01000)来判断高位是否是 1,这里只有两种情况,要么是 1 要么是 0 。

从上面的源码可以看到,链表的数据是一次性计算完,然后一堆搬运的,因为扩容时候,节点的下标变化只会是原位置,或者原位置+老数组长度,不会有第三种选择。
上面的位操作,包括为什么是原下标+老数组长度等,如果你不理解的话,可以举几个数带进去算一算,就能理解了。
总结一下,1.8 的扩容不需要每个节点重写 hash 算下标,而是通过和老数组长度的**&**计算是否为 0 ,来判断新下标的位置。
额外再补充一个问题:为什么 HashMap 的长度一定要是 2 的 n 次幂?
原因就在于数组下标的计算,由于下标的计算公式用的是 i = (n - 1) & hash,即位运算,一般我们能想到的是 %(取余)计算,但相比于位运算而言,效率比较低,所以推荐用位运算,而要满足上面这个公式,n 的大小就必须是 2 的 n 次幂。
即:当 b 等于 2 的 n 次幂时,a % b 操作等于 a & ( b - 1 )
头插法和尾插法
1.7是头插法,上面的图已经展示了。
头插法的好处就是插入的时候不需要遍历链表,直接替换成头结点,但是缺点是扩容的时候会逆序,而逆序在多线程操作下可能会出现环,然后就死循环了。
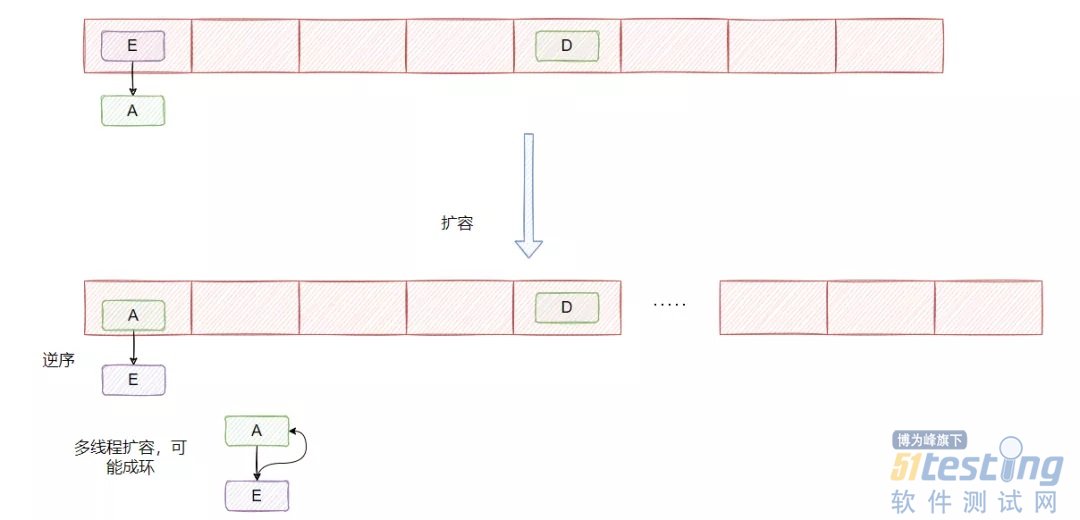
然后 1.8 是尾插法,每次都从尾部插入的话,扩容后链表的顺序还是和之前一致,所以不可能出现多线程扩容成环的情况。
那为什么要变成尾插法呢?我也没找到官方解答,如果有谁知道可以教我一下。
那再延伸一下,改成尾插法之后 HashMap 就不会死循环了吗?
打印本页 | 加入收藏
上一篇:测试开发和纯软件开发哪个更好? 下一篇:我今年30了,只会功能测试怎么办?
文章检索
热门关键词: 登录