不吹牛,吃下我这篇,面试第一关算是过了(1)
时间: 2022-02-11 10:46 作者: liqianqian1116 点击次数:
你好,我是yes。
这篇来盘盘集合类的面试题,这玩意被问的几率很高,算是基础中的基础了,几乎一面必定会涉及到一两题,所以需要好好关注下。
我这篇几乎把集合相关核心面试点都盘了,可以说吃下这篇,这关差不多稳了。字挺多的,建议收藏先。
对了,这篇过段时间也会收录到我的面试仓库,上面已经有很多面试题啦,求个 star!
https://github.com/yessimida/interview-of-legends
好了,不吹牛了,我们发车!
说说Java的集合类
这题一般用在开头,让你热热身,你也不需要说的那么详细,大致讲下,面试官会根据你回答的点继续挖的。
Java集合从分类上看,有 collection 和 map 两种,前者是存储对象的集合类,后者存储的是键值对(key-value)

Collection
Set
主要功能是保证存储的集合不会重复,至于集体是有序还是无序的,需要看具体的实现类,比如 TreeSet 就是有序的,HashSet 是无序的(所以网上有些说 set 是无序集合是在扯淡)
List
这个很熟悉,具体的实现类有 ArrayList 和 LinkedList,两者的区别在于底层实现不同,前者是数组,后者是双向链表,所以引申出来就是将数组和链表的区别。
数组 VS 链表
数组的内存是连续的,且存储的元素大小是固定的,实现上是基于一个内存地址,然后由于元素固定大小,支持利用下标的直接访问。
具体是通过下标 * 元素大小+内存基地址算出一个访问地址,然后直接访问,所以随机访问的效率很高,O(1)。
而由于要保持内存连续这个特性,不能在内存中间空一块,所以删除中间元素时就需要搬迁元素,需进行内存拷贝,所以说删除的效率不高。
链表的内存不需要连续,它们是通过指针相连,这样对内存的要求没那么高(数组的申请需要一块连续的内存),链表就可以散装内存,不过链表需要额外存储指针,所以总体来说,链表的占用内存会大一些。
且由于是指针相连,所以直接无法随机访问一个元素,必须从头(如双向链表,可尾部)开始遍历,所以随机查找的效率不高,O(n)。
也由于指针相连这个特性,单方面删除的效率高,因为只需要改变指针即可,没有额外的内存拷贝动作(但是要找到这个元素,费劲儿呀,除非你顺序遍历删)。
两者大致的特点就如上所说,再扯地深一点,就要说到 CPU 亲和性问题
各位应该都听过空间局部性。
空间局部性(spatial locality):如果一个存储器的位置被引用,那么将来它附近的位置也会被引用。
根据这个原理,就会有预读功能,像 CPU 缓存就会读连续的内存,这样一来如果你本就要遍历数组的,那么你后面的数据就已经被上一次读取前面数据的时候,一块被加载了,这样就是 CPU 亲和性高。
反观链表,由于内存不连续,所以预读不到,所以 CPU 亲和性低。
对了,链表(数组)加了点约束的话,还可以用作栈、队列和双向队列。
像 LinkedList 就可以用来作为栈或者队列使用。
queue
队列,有序,严格遵守先进先出,就像往常的排队,没啥别的好说的。
常用的实现类就是 LinkedList,没错这玩意还实现了 Queue 接口。
还有一个值得一提的是优先队列,即 PriorityQueue,内部是基于数组构建的,用法就是你自定义一个 comparator ,自己定义对比规则,这个队列就是按这个规则来排列出队的优先级。
Map
存储的是键值对,也就是给对象(value)搞了一个 key,这样通过 key 可以找到那个 value。
最出名的,平日里使用最多的应该就是 HashMap,这个是无序的。
还有两个实现类,LinkedHashMap 和 TreeMap,前者里面搞了个链表,这样塞入顺序就被保存下来了,后者是红黑树实现了,所以有序。
最后还有个 IdentityHashMap ,这个好像网上文章都提的比较少,不过我们也来盘一下,有备无患。
HashMap
这玩意是面试高频点,可以说几乎被问烂了... 有的题目还很刁难,比如问默认初始容量(16)是多少,哈希函数怎么设计的..没点准备肯定蒙,所以我们来个一网打尽。
能说下 HashMap 的实现原理吗?
其实就是有个 Entry 数组,Entry 保存了 key 和 value。当你要塞入一个键值对的时候,会根据一个 hash 算法计算 key 的 hash 值,然后通过数组大小 n-1 & hash 值之后,得到一个数组的下标,然后往那个位置塞入这个 Entry。
然后我们知道,hash 算法是可能产生冲突的,且数组的大小是有限的,所以很可能通过不同的 key 计算得到一样的下标,因此为了解决 Entry 冲突的问题,采用了链表法,如下图所示:
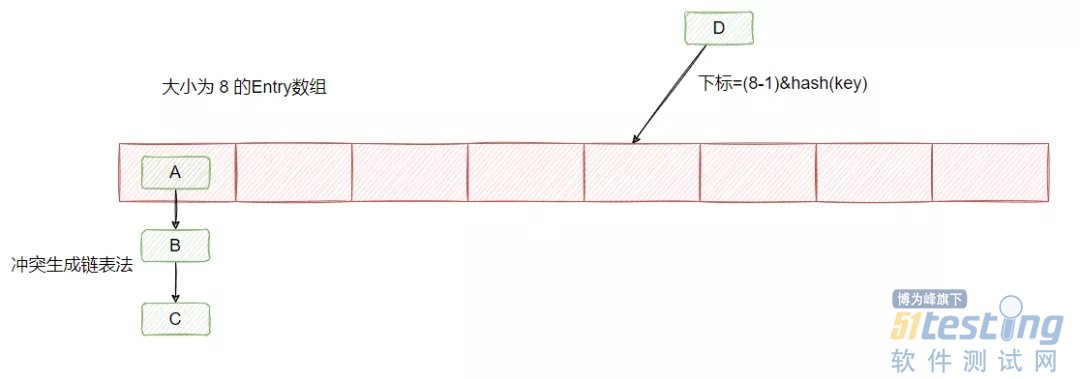
在 JDK1.7 及之前链表的插入采用的是头插法,即在链表的头部插入新的 Entry。
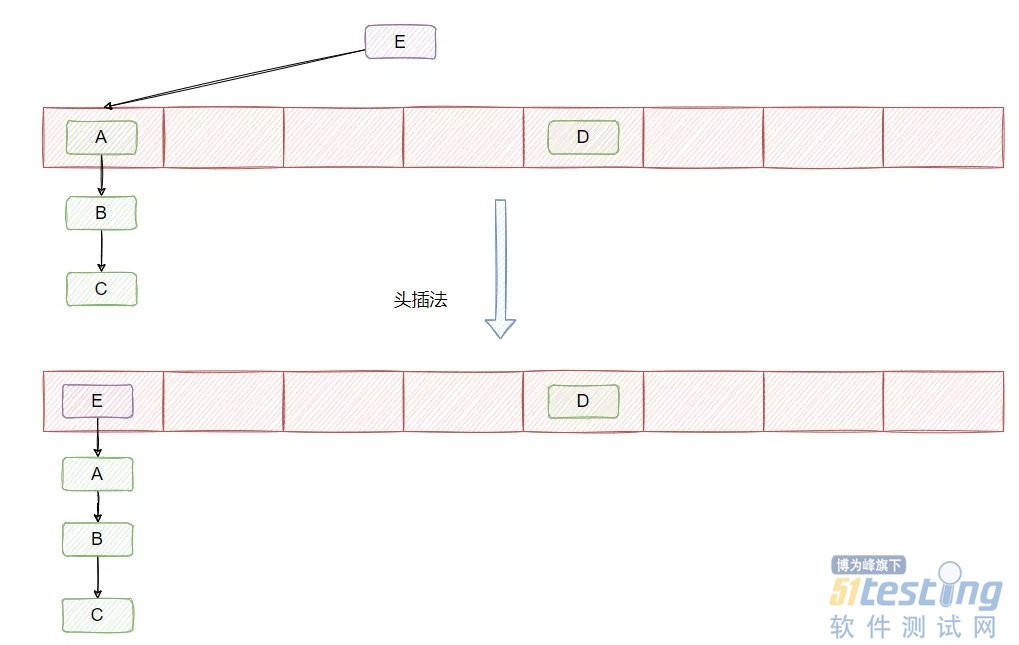
在 JDK1.8 的时候,改成了尾插法,并且引入了红黑树。
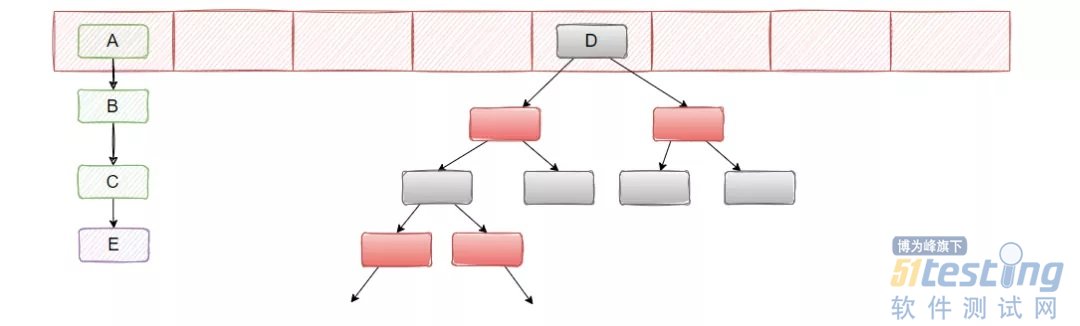
当链表的长度大于 8 且数组大小大于等于 64 的时候,就把链表转化成红黑树,当红黑树节点小于 6 的时候,又会退化成链表。

打印本页 | 加入收藏
上一篇:新人软件测试工程师必须知道的,不然为时已 下一篇:你们觉得软件测试和软件开发,哪个更有发展
文章检索
热门关键词: 登录