- 您的位置:首页>测试职场规划>通过数据分析小窥测试行业现状
通过数据分析小窥测试行业现状
时间: 2021-10-19 16:30 作者: 谢小玲 点击次数:
通过前面的爬虫,我们可以得到一些数据,通过数据分析,可以得到一些结论。
现在各个公司都在搞大数据,前段时间支付宝大数据分析我们的年度账单。
我们普通人也可以搞搞大数据,通过数据分析,来决策我们的生活。
可以爬取股票或者财经数据,来分析走势或者判断那个收益更高。
可以爬取电商数据,来判断那个商品性价比更高,更受欢迎。
爬取微博,各种新闻以及评论,看事态如何发展,看别人如何看待热点事件的。
爬取美食,决定去哪里吃饭。
爬取豆瓣电影,看看哪部电影值得去看看。
虽然很多网商都有评价系统,但是很多并不能代表我的想法。比如大众点评上,可以看热度,口味,环境,服务,价格,距离等。但是数据太多,一个一个看不过来。
而且我可能认为服务占比低,价格和口味我比较看重,系统的推荐不符合我的需求。我可以从中爬取数据,通过数据分析,按照我的衡量标准综合考量,达到我的目的。
对于外地人来说,租房或者买房,比较头疼,没有那么多时间实地查看,网上的信息似乎又不那么靠谱,有灌水的,刷单的。而且中介的最说得天花乱坠。怎么办,只能自己搜集信息,做初步的筛选,避免浪费很多无谓的时间。
如何分析数据呢? 给大家介绍一个数据分析利器―pan das。
Pan das 是python的一个数据分析包,Pan das最初被作为金融数据分析工具而开发出来,因此,pan das为时间序列分析提供了很好的支持。 Pan das的名称来自于面板数据(panel data)和python数据分析(data analysis)。
该工具是为了解决数据分析任务而创建的。Pan das 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pan das提供了大量能使我们快速便捷地处理数据的函数和方法。
可以通过传递一个list对象来创建一个Series,pan das会默认创建整型索引:

通过传递一个numpy array,时间索引以及列标签来创建一个DataFrame:
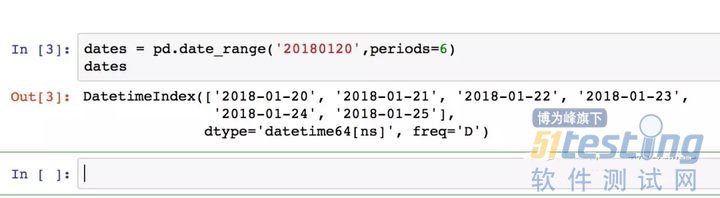
这里不花大量篇幅来讲它,大家可以去官网学习。
其实他主要就是一个二维列表DataFrame(很方便的加index, colum)
很方便的转换数据(汇总,缺失,索引)
很方便的处理清洗数据(清理,转换,合并)
很方便的加载存储数据(文本,csv,excel,数据库,html)
很方便聚合与分组运算(GroupBy)
绘图和可视化(matplotlib)
总之,很方便的处理大量的数据。
现在就继续分析testerhome, 假如我想知道:最近一年以来,精华贴里面评论最多的是哪些。
于是我爬精华贴里的评论数。
import os
import re
import numpy as np
import pan das as pd
import requests
from bs4 import BeautifulSoup
spider_url = "https://testerhome.com/topics/excellent"
max_page = 30
def get_page(myurl):
try:
result = requests.get(myurl)
if result.status_code != 200:
print("fail")
else:
return result.content
except Exception as e:
print(e)
def get_detail(num):
result = []
if num >= 2:
get_url = spider_url + "?page={}".format(num)
else:
get_url = spider_url
page = get_page(get_url)
soup = BeautifulSoup(page, ”lxml”)
acCount = soup.Select(”div.Count.media-right a”)
topic_re = "topics/(d+)#"
acCount_re = ">(d+)</a>"
m = re.findall(topic_re, str(acCount))
n = re.findall(acCount_re, str(acCount))
result.append(m)
result.append(n)
result_frame = pd.DataFrame(result)
topic_frame = result_frame.T
topic_frame.to_csv(path_or_buf="topic_frame.csv", header=False, index=False, mode=”a+”)
其实这里取了点巧,评论数为0的,直接不爬出来,我就不需要清洗这样的数据了。

得出一个这样的列表。
这个列表看不出什么,只能得到精华帖的pageid,以及评论数,继续分析
if __name__ == "__main__":
if os.path.exists("topic_frame.csv"):
print("is ok")
read_topic_frame = pd.read_csv("topic_frame.csv", names=["url", "acCount"])
final_frame = read_topic_frame.sort(["acCount"], ascending=False).head(10)
print(final_frame)
urls = final_frame[”url”]
my_hosts = []
for url in urls:
host = "https://testerhome.com/topics/{}".format(url)
my_hosts.append(host)
final_frame[”url”] = np.array(my_hosts)
print(final_frame)
final_frame.to_csv(path_or_buf="topic_top.csv", header=True, index=True)
else:
print("file not exist, need to spider")
for page_index in range(max_page):
get_detail(page_index)
我就按从高到低,取前10, 其实很简单,一条语句就排序获取了前10.
final_frame = read_topic_frame.sort(["acCount"], ascending=False).head(10)
得到的结果如下:
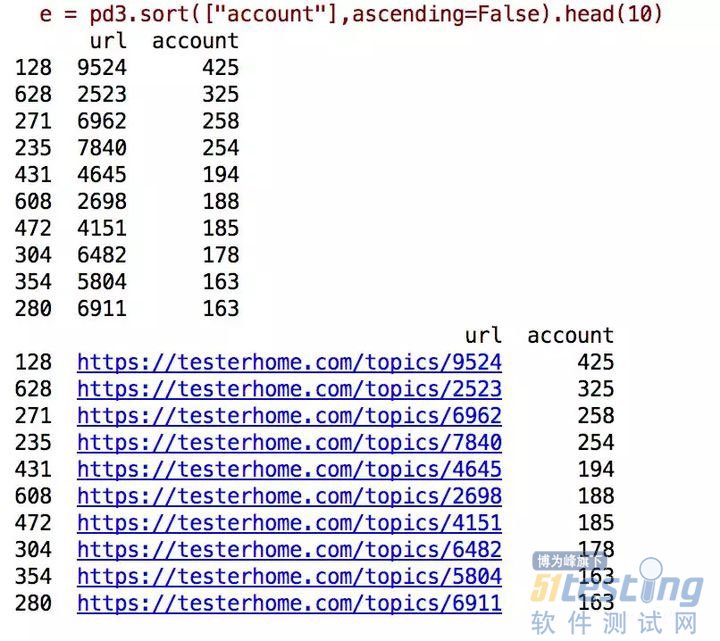
只知道链接,并不知道文章是什么,继续,得到:

从中可以看出:
大家对创新的,实用的工具,关注比较多。
对基本的环境安装,也关注多,看来新手比较多。
虽然现在AI,大数据等比较火,坛子里也有不少人探索和分享,但毕竟关注的人不多,都没排进前10.
只是用坛子里的数据,做了简单的数据分析,可能不太准,也能看出当前测试发展的一些现状。
打印本页 | 加入收藏
上一篇:测试开发工程师常见面试题 下一篇:9道软件测试面试题,刷掉90%的软件测试
文章检索
热门关键词: 登录